

作家:周雅哥哥干
作家|周雅
NVIDIA创举东说念主黄仁勋在CES 2025的全程高能演讲,浅看是一场新品发布会,实则是英伟达下了一步巨大的棋,这步棋关乎从云霄到终局、从数据中心到闲居用户、从捏造寰宇到物理寰宇的“全场地”AI发展阶梯,不外这个“全”带了引号,因为英伟达试图在每一个标的皆去突破既有玩法的极限。
就像黄仁勋在会后给与包括至顶科技在内的媒体采访时所说:“英伟达只作念两类事情:要么是别东说念主没在作念的,要么是咱们能作念得私有且更好的。”
是以从这个角度,再回看那场发布会,似乎是另外的基调,是以这篇著述特此梳理黄仁勋此次演讲背后的8个中枢重点。

图:出当今CES 2025舞台上的黄仁勋,此次穿了件闪亮亮的皮衣,他开打趣地对不雅众说说念:“毕竟我在拉斯维加斯”。
重点一:“AI改变了游戏规定,改动变了计较的本色”,是以用BlackWell重新界说AI计较的界限。
黄仁勋开篇回想了英伟达的发展历程。
从1993年NV1开动,英伟达就立志,构建能完成闲居计较机无法完成任务的计较机,其时英伟达的编程架构被称为UDA(Unified Device Architecture,调和设备架构),跑在UDA的第一个应用方法,是世嘉的《捏造战士》。

六年后的1999年,NVIDIA发明了可编程GPU;又过了六年后的2006年,英伟达发明了通用并行计较架构CUDA(Compute Unified Device Architecture);再过了六年后的2012年,跟着“师生三东说念主组”Alex Krzyzewski、Ilya Suskevor和Jeffery Hinton欺诈GPU教育AlexNet,并赢得2012年ImageNet挑战赛,惊怖了计较机视觉界,AI由此参预新阶段。(这几个6年历程,老铁见了皆得直呼666)
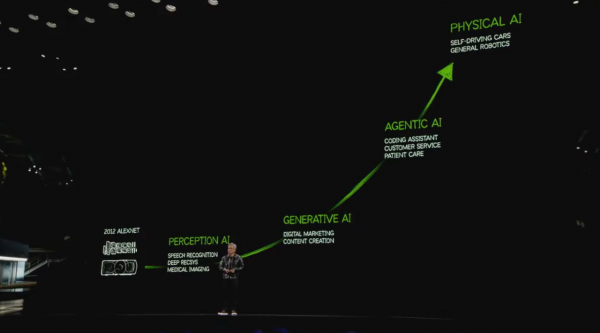
黄仁勋认为,AI发展有四个阶段:
1、感知AI(Perception AI),交融图像、翰墨和声息,场景包括语音识别、推选系统、医学成像;
2、生成式AI(Generative AI),生成图像、文本和声息,场景包括数字营销、内容生成;
3、现阶段的Agenic AI,大约感知、推理、接头和步履,场景包括代码助理、客户工作、患者照应;
4、异日的物理AI(Physical AI),场景包括自动驾驶汽车、通用机器东说念主。
2018年是一个关键的节点,谷歌发布Transformer模子BERT,绝对改变了AI的口头。这里温馨插入一段解释,之是以说Transformer具有变革性,是因为它引入的注见地机制,措置了长序列数据处理的艰苦,且允许并行计较,冲突了传统RNN和LSTM的串行限制,它让机器第一次着实学会了“看全局”。
淌若说已往的AI是只可一个个字往下读,但会看了后边忘了前面的儿童,而Transformer等于一目十行,心有全篇的行家。这个突破不仅让AI更聪惠,处理信息的速率也贼快。而且它犀利的地方是,不光能处理翰墨,连图片、声息这些皆能粗疏。是以说,Transformer就像是AI寰宇的“基本法”,绝对改变了AI的发展标的。
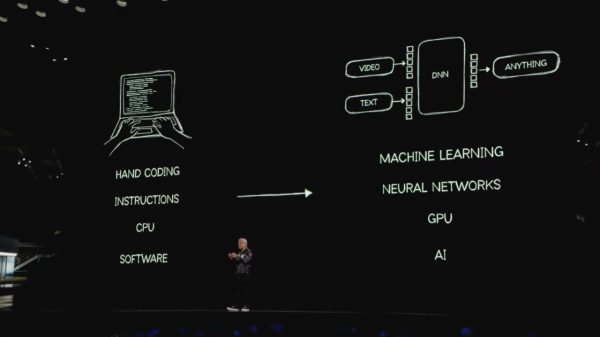
黄仁勋现场说:“Transformer驱动的机器学习将从根柢上改变每一个应用方法的构建姿首、计较姿首、以及超越这些的可能性。”
顺着这句话,黄仁勋举了个“AI改革传统图形渲染”的例子。传统明后跟踪,要对每个像素进行复杂计较,计较量巨大,但AI变革了这个经过——英伟达在游戏图形领域完成了两次根人性的改革:
第一次改革是引入可编程着色器和明后跟踪技巧,这让显卡大约通过定制化的方法来处理像素,并模拟确切寰宇中的明后步履,从而生成极具确切感的画面;第二次改革是DLSS(AI超诀别率技巧,Deep Learning Super Sampling),它的核脸色念是让AI来援助以致部分取代传统的像素渲染,通过在英伟达超等计较机上进行大鸿沟教育,AI系统学会了交融和预测像素的脸色值,使得GPU上的神经集会大约“脑补”出未经实践渲染的像素内容。
最新一代DLSS 4的突破,被黄仁勋称之为“遗迹”,它不仅能在空间维度上补全像素,还能在时期维度上职责——通过预测异日画面,为每一帧罕见生成三帧画面,就好比有3300万像素,而实践只需计较200万像素,并让AI预测其余的3100万像素,既保证了渲染质料,又擢升了渲染后果。在现场演示中,DLSS 4 以每秒247帧的速率渲染场景,比不使用AI快8倍以上,同期将延伸保持在仅34毫秒。
顺着上述知识点,黄仁勋发布了此次的第一款GPU新品——RTX Blackwell系列。

RTX Blackwell 系列领有920亿个晶体管,AI算力最高达4000 TOPS(比上一代高出三倍),好意思光G7内存,带宽可达每秒 1.8 TB(是上一代性能的2倍)。现存的 RTX GPU 也将复古 DLSS 4。

该系列包括四种型号:
RTX 5070——售价549 好意思元,提供 RTX 4090 的性能。
RTX 5070 Ti——售价749 好意思元,提供与 4090 特地的性能,配备 1406 AI TOPS 和 16GB G7 内存。
RTX 5080——售价999 好意思元,配备 1800 AI TOPS 和 16GB G7 内存。
RTX 5090——售价1999 好意思元,配备 3404 AI TOPS 和 32GB G7 内存。

搭载 RTX Blackwell GPU 的札记本电脑,电板寿命延长 40%,性能提高一倍,功耗缩小一半,价钱从1299 好意思元到 2899 好意思元不等。其中,搭载RTX 5090、RTX 5080、RTX 5070 Ti的笔电将于3月上市,搭载RTX 5070笔电将于4月由OEM发售。

重点二:“Scaling Law依然见效,正鼓舞AI计较需求的指数级增长”,是以用NVLink满足大家数据中心需求。
接着讲到AI发展,黄仁勋认为Scaling Law(鸿沟定律)还充公尾——即数据越多、模子越大、计较才气越强、模子就越灵验。之是以还充公尾,是因为互联网每年产生的数据量皆在翻倍,异日几年东说念主类产生的数据量将卓越之前的总数,而且这些数据正变得多模态。
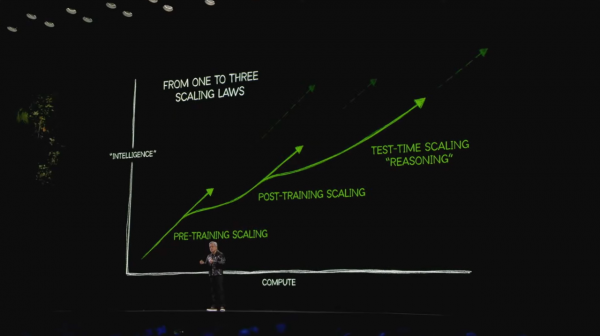
黄仁勋认为,鸿沟定律非但充公尾,而且还发展出三种气象:预教育鸿沟定律(Pre-Training Scaling)、后教育鸿沟定律(Post-Training Scaling)、测试时期鸿沟定律(Test-Time Scaling)。
其中:
「预教育鸿沟定律」欺诈强化学习和东说念主工反馈等技巧,AI借助东说念主类反馈进行学习擢升,它不错针对特定领域微调,访佛学生字据敦厚教导改进功课,适当措置数学、推理问题。
「后教育鸿沟定律」则访佛于自我训诫,AI通过不息自主训诫擢升才气,经过中虽奢侈多数算力,但能产生突破性模子。
「测试时期鸿沟定律」是指AI运行时,不再只是改进参数,而是能动态掉配计较资源,通过“分步推理”和“深入想考”找出最优措置决策。该定律已被评释注解极其灵验。
黄仁勋说,“鸿沟定律鼓舞了对英伟达的计较,止境是Blackwell芯片的巨大需求。”

图:Blackwell全系家具图
丝袜色情话音落下,黄仁勋搬出了一个由72块Blackwell GPU构成的NVLink72巨型“盾牌”模子,还摆了个pose,被网友捉弄“好意思国队长”。


不外黄仁勋手里的“盾牌”,只是NVLink72的缓慢模子,着实的NVLink72重达1.5吨,领有60万个零件,特地于20辆汽车的复杂进程,系统里面有个访佛“脊椎”的结构,通过2英里的铜线与5000根电缆把统共的Blackwell链接在一说念。

黄仁勋先容了性能参数。一个NVLink72芯片的AI浮点运算性能是1.4 ExaFLOPS,比寰宇上最大、最快的超等计较机还要大。其内存带宽达到 1.2 PB/s,特地于大家统共互联网流量的总数。这种超等计较才气,使得 AI 大约处理更复杂的推理任务,同期显贵缩小资本,为更高效的计较奠定了基础。

NVLink72的出产和部署经过十分复杂。它在大家45个工场进行出产,领受液冷技巧散热,经过严格测试后会被拆解成小部件,运输到大家的数据中心,之后再重新拼装起来——这种特殊的运输姿首是因为整机太重太大。
黄仁勋解释了“为什么要建造这块大而无当”,是因为Scaling Law要求越来越刚劲的计较才气。新一代Blackwell芯片与上一代比较,每瓦性能擢升了4倍,每好意思元性能提高了3倍。这个擢升带来两个蹙迫影响:
第一,从资本角度看,教育相通鸿沟的AI模子,资本不错缩小到蓝本的1/3;或者用换取资本,不错教育鸿沟大3倍的模子。
第二,从数据中心运营角度看,由于数据中心受限于供电才气,新芯片的能效擢升意味着,在换取供电条款下,数据中心不错进行4倍于之前的AI运算,这平直治疗为更高的营收才气。
黄仁勋强调,这种擢升相当蹙迫,因为异日简直统共应用皆会使用AI进行文本处理(tokens)。咫尺大模子的token生成速率为每秒20-30个,与东说念主类阅读速率特地。但在异日,GPT-o1/o2/o3、Gemini Pro等新模子大约进行自我对话、想考、反想,因此token的生成速率将大幅提高,而这些处理皆需要在数据中心进行,他将这些数据中心比方为“AI工场”,而新一代芯片的能效擢升,本色上等于在提高这些“AI工场”的出产后果。
重点三:“Agenic AI是企业最蹙迫的变革之一”,是以英伟达挟制利诱。
黄仁勋形色了一个令东说念主高亢的AI异日图景——“Agenic AI将成为企业最蹙迫的变革之一。”这种变革不仅是技巧的越过,更是职责姿首的根柢治疗。
在他的形色中,AI代理不再是简单的问答系统,而是一个复杂的智能集会,它大约交融用户需求,搜索信息、调用各式器具、并通过多个模子的协同职责,来匡助用户措置问题。
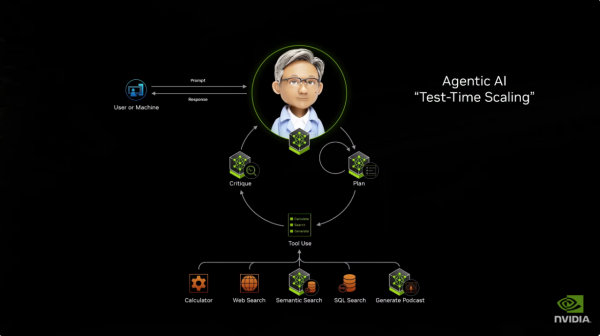
为了匡助企业和配联合伴杀青Agenic AI的异日图景,英伟达推出了三个蹙迫家具:
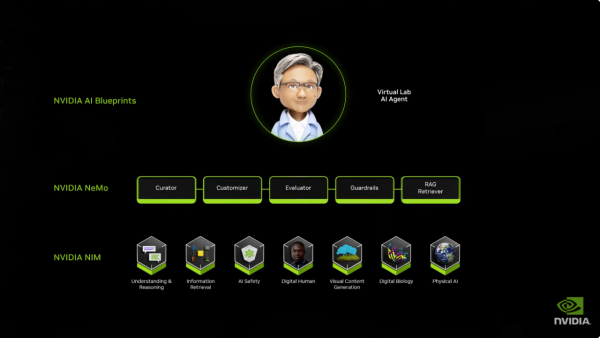
第一个是NVIDIA NIMS,这是一套打包好的AI微工作,包含CUDA DNN、Cutlass、Tensor RTLM、Triton等CUDA软件,以及一系列模子(涵盖语义交融、数字东说念主、捏造内容生成、数字生物等领域,并行将上线“物理AI”模子),便捷开发者集成到自己软件中,不错在大部分云平台上运行。
第二个是NVIDIA NEMO,这是一个“数字职工”管制系统,负责教育AI智能体适合企业特定需求、竖立步履准则和权限、而况通过反馈不停改进,就像是给AI代理作念“入职培训”。
第三是一整套AI Blueprints(AI蓝图),以便生态系统伙伴和开发者自主构建AI智能体,而且它足够开源。黄仁勋先容了其中的一套模子——Llama Nemotron开源模子套件,这是一个企业级话语模子的“全家桶”,是英伟达针对Meta的Llama进行微调而成(黄仁勋解释说,是因为英伟达发现Llama 3.1如故成为一个征象级家具,它被下载65万次,养殖出了6万个不同版块,是大部分企业研发AI的开动,而且不错它能被很好地微调)。
英伟达的Llama Nemotron包括三种规格:
Nano:极其工致、反应快、最具资本效益的模子,针对PC和旯旮设备所需的低时延模子进行了优化;
Super:在单个GPU上提供超卓迷糊量的高精度模子;
Ultra:精度最高的模子,专为要求最高性能的数据中心鸿沟应用而盘算。

黄仁勋预测,异日企业的IT部门将治疗成AI智能体的HR部门,它们不再只是是景仰软件系统,而是要管制一支数字劳能源戎行。大家有3000万方法员和10亿知识职责者将受益于这场变革,AI智能体将成为他们的给力助手。
这种AI智能体带来的变革,正在影响九行八业,黄仁勋在现场通过一支视频展示了5种AI代理的应用场景:
AI磋议助手:在磋议领域,AI智能体不错快速处理讲座、期刊、财报等复杂尊府,生成易于交融的内容;
天气预告系统:在表象预告中,AI智能体将预告精度从25公里擢升到2公里;
软件安全AI:在软件开发经过中,AI智能体不错自动扫描代码间隙并冷落迷惑建议;
捏造实验室:在制药磋议中,AI智能体不错匡助磋议东说念主员快速筛选药物候选物,加快新药研发经过。
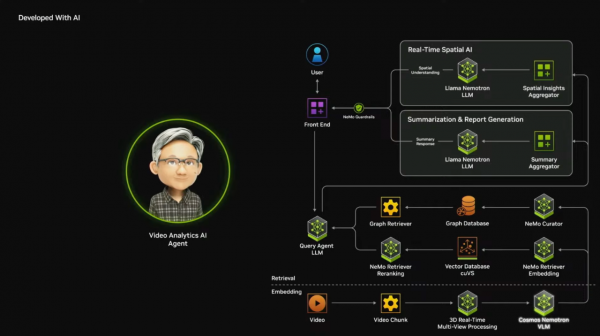
英伟达选拔了一条私有的市集旅途。他们不服直面向企业用户,而是与生态系统的配联合伴一说念职责,就像当年执行CUDA一样。生态系统中的配联合伴有CrewAI、Daily、LangChain、LlamaIndex、Weights & Biases的器具,也有ServiceNow、SAP、西门子的工业平台,也有甲骨文、dataloop的数据平台等。英伟达正在将AI代理渗入到各个行业。

这个政策显现了英伟达对异日AI的潜入交融:AI代理不仅是一个技巧家具,而是企业的“数字职工”,它们需要培训、管制和不息改进,就像管制东说念主类职工一样,这些AI代理可被教育为领域特定的任务行家。

通过这番演讲,黄仁勋展现了一个AI代理与东说念主类协同职责的异日。在这个异日中,企业将领有一支由东说念主类+AI代理构成的劳能源戎行,该戎行是鼓舞出产力擢升的蹙迫力量,而英伟达正在通过完整的技巧决策和生态系统建设,来匡助企业杀青这个异日。
重点四:“将Windows PC治疗为AI超等计较机”,是以英伟达发布了WSL2。
说收场Agenic AI的愿景之后,如何才能着实落地呢?黄仁勋的谜底是——腹地算力:
“固然云霄计较对AI 来说是竣工的选拔,但AI的异日不应该仅限于云霄,而是应该无处不在,止境是要参预咱们的个东说念主电脑。就像Windows 95改革了个东说念主计较时间一样,异日的PC将草创新的计较范式,让每个用户皆大约充分欺诈AI的力量来擢升职责后果和创造力。”
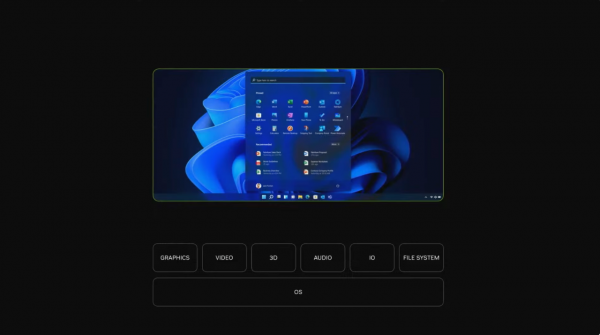
从这个角度来看,黄仁勋先容了异日PC的办法:不再只是简单地领有3D、声息和视频API,而是要具备各式生成式API的才气(包括3D生成、话语生成、声息生成等),这意味着每台电脑皆将成为一个刚劲的AI助手。

英伟达提供了一个措置决策:Windows WSL2(Windows Subsystem for Linux 2),这是一个Window系统内的双操作系统,为开发者提供平直看望硬件的才气,而况如故针对云原生应用和CUDA进行了优化,这使得包括NVIDIA NIMS、NVIDIA NEMO在内的统共AI器具皆能在Windows PC上运行。
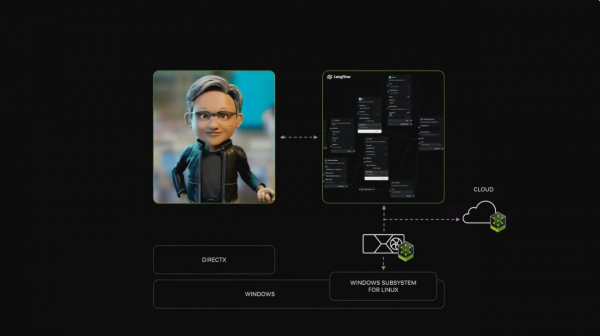
通过WSL2,英伟达不错将其统共AI器具和工作带到个东说念主电脑上,包括各式模子。换句话说,这是一种计较范式的治疗——每台个东说念主电脑皆将成为一个刚劲的AI职责站。
重点五:“咱们要创造一个物理寰宇的AI模子”,是以英伟达发布Cosmos。
黄仁勋接下来的演讲内容,我认为是本场最蹙迫亦然英伟达接下来最蹙迫的政策布局,我合计不错交融为“让AI化形”。
什么料想?淌若说GPT等鬼话语模子让AI掌捏了“说”的才气,那么英伟达但愿创造一个能交融物理寰宇的AI系统,赋予AI“作念”的才气,这预示着AI行将从捏造寰宇走向现实寰宇的蹙迫一步。
接下来咱们就迟缓来讲讲。
黄仁勋来源说,当咱们使用ChatGPT这么的话语模子时,咱们输入一段教唆词,模子会分析这段翰墨中的每个词语(token)之间的策动,然后一个接一个地生成回复的词语。这个经过看似简单,实践上模子里面少见十亿个参数在运作,每个词语皆要和高下文中的其他词语建树策动,计较它们之间的有关性。
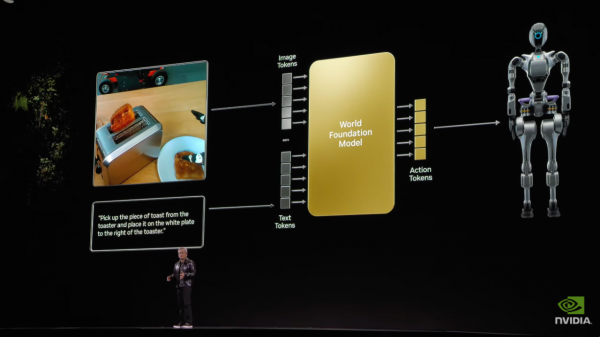
然则,咱们活命的现实寰宇比文本复杂得多,AI需要交融重力、摩擦力、惯性等物理规章,还要显然空间策动和因果策动。比如,当你把球推出去时,它会如何开通;当你推倒一个物体时,会发生什么;物体从桌子上掉下去后,并不会隐没——这些在东说念主类看来很简单的学问,对AI来说皆是巨大的挑战。
为了达成这个极具挑战性的“让AI交融物理寰宇”办法,于是英伟达厚爱推出Cosmos——一个刚劲的、能交融物理寰宇的、大家基础模子。
Cosmos是如何职责的?就像婴儿通过不雅察、触摸、实验来意志这个物理寰宇,Cosmos通过看多数视频来学习物理寰宇的规章,就像是一个加快学习的婴儿。黄仁勋说,Cosmos如故学习了2000万小时的视频,内容包括:当然征象(水会若何流动)、物理规章(物体会如何碰撞)、东说念主类动作(东说念主是如何步碾儿和抓取物品的)等。这些皆成为它交融物理寰宇的“教化”。
然则,Cosmos的作用远不啻于此。黄仁勋说,因为有Cosmos,咱们不错因此创造一个物理寰宇的基础模子,基于Autoregressive Model(自记忆模子)、Diffusion Model(扩散模子)、Video Tokenizer(将视频内容编码为紧凑的潜在token)、Video Processing and Curation Pipeline(视频处理管说念)。
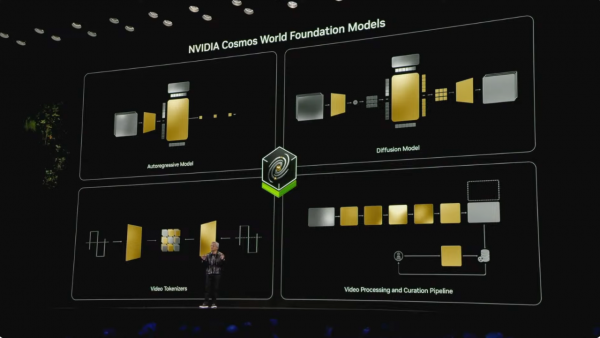
比如,它不错用来生成教育数据,匡助开发更智能的机器东说念主,被黄仁勋比方成“机器东说念主的种子”;它能生成多种异日的物理场景,匡助AI作念出更好的决策,“就像是一个奇异博士”;它以致不错为视频生成准确的形色,这些形色又不错用来教育话语模子。
最蹙迫的是,英伟达选拔将Cosmos开源,就像Meta开源Llama一样。黄仁勋示意,但愿Cosmos能为机器东说念主和工业AI领域带来访佛Llama 3.1对企业AI的立异性影响。
当今关键来了:当Cosmos与英伟达的捏造现实仿真平台Omniverse连络时,这就像是给AI创造了一个“物理寰宇的实验场”,让它能在这里学习、实验和成长,它就能创造出基于确切物理规章的捏造寰宇。
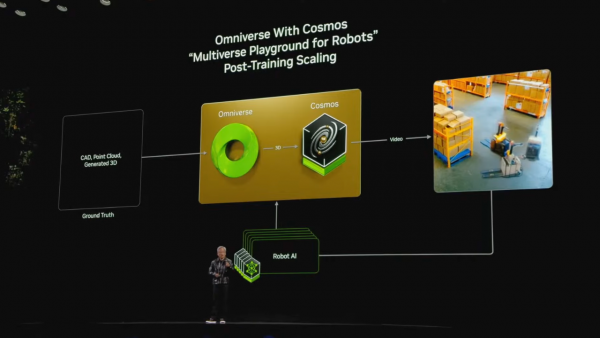
这里梳理一下黄仁勋的解释:Omniverse是一个基于物理规章运行的模拟器,而Cosmos则不错交融为一个物理寰宇的AI生成系统。当这两个系统连络时,这就像是咱们在用鬼话语模子时,通过RAG(检索增强生成)系统来确保AI生成的内容是基于确切信息一样。在这里,Omniverse的物理模拟确保了Cosmos生成的内容合适现实寰宇的物理规章。
黄仁勋用了一个很好的类比:就像咱们需要让话语模子的输出建树在确切信息的基础上一样,咱们也需要让机器东说念主的步履建树在确切物理规章的基础上,这么的连络创造出了一个“基于物理规章的多元天地生成器”。
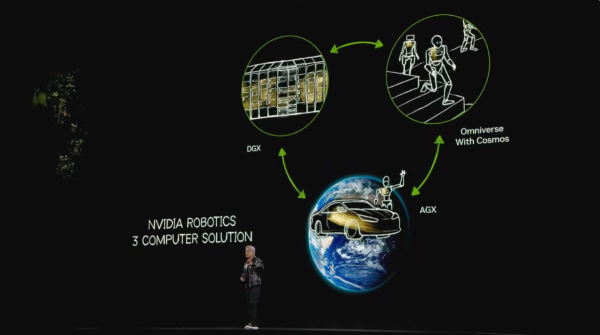
在实践应用中,这种连络止境适当机器东说念主和工业应用场景。正因为如斯,黄仁勋冷落了一个“三个计较机系统”办法:
第一个计较机系统(DGX)是用来教育AI的。这就像是机器东说念主的“学校”,在这里进行基础的AI教育。
第二个计较机系统(AGX)是部署在实践场景中的,比如装置在自动驾驶汽车里、机器东说念主身上或者开通场馆中的计较机。这些是在“前方”职责的计较机,负责实践的自主操作。
第二个计较机系统恰是Omniverse+Cosmos系统,它是一个数字孪生平台。这就像是机器东说念主的“捏造教育场”。在这里,如故教育好的AI不错进行训诫、完善,通过合成数据生成和强化学习,来擢升性能。这个系统将前两个系统链接起来,使它们大约协同职责。
为什么需要Cosmos+Omniverse?因为假定你在教一个孩子学物理,弗成能让孩子去作念统共危机的实验,比如从高处跳下来感受重力,或者去碰滚热的物体了解温度。而Omniverse就提供了一个“捏造实验场”:比如不错无尽尝试各式动作,而无用系念损坏确切设备;或者,快速模拟数千种不同的场景,而无用系念时期不够;或者测试各式顶点情况,而无用承担实践风险。
这种组合的刚劲之处还在于:一方面,就算AI出错,也不会酿成实践耗损,不错立即重来。另一方面,Cosmos通过不雅察视频学习到的“教化”,不错在Omniverse中得到考据和完善。
黄仁勋止境强调了Omniverse+Cosmos系统在工业领域的蹙迫性:“大家制造业大致有50万亿好意思元的鸿沟,包括数以百万计的工场和数十万个仓库,这些设施皆需要向软件界说和自动化标的发展。非论是工场的自动化系统,如故自动驾驶汽车,皆需要这么的系统,来保证其步履既合适AI的智能决策,又合适现实寰宇的物理规章。”

图:英伟达Omniverse的配联合伴生态系统
也因此,黄仁勋预测:工业出产正在向数字化、智能化标的发展,数字孪生将成为异日每一个工场的标配,它就像工场的“捏造分身”,大约足够模拟确切工场的运作,通过Omniverse+Cosmos系统,不错模拟出多种异日可能的运营决策,然后让AI选拔最优决策,这些决策会成为确切工场的运营教导。

重点六:“三个计较机系统”表面构筑自动驾驶异日,是以英伟达带来了Thor。
接着,黄仁勋谈到了自动驾驶立异,又秀出一张生态配合图,展示了英伟达在自动驾驶领域的泛泛配合,遮盖Waymo、特斯拉、捷豹路虎、疾驰、丰田,还有比亚迪、梦想、小鹏等纷乱中国车企。

黄仁勋提供了一组数据:大家每年出产1亿辆汽车,说念路上有10亿辆车,每年行驶里程达到1万亿英里。他预测,“这些车辆异日皆将杀青高度自动化或足够自动化驾驶,这代表自动驾驶很可能成为第一个万亿好意思元级别的机器东说念主产业。”咫尺,只是是小数开动量产的自动驾驶汽车,就如故为英伟达带来了40亿好意思元收入鸿沟,瞻望本年将达到50亿好意思元。
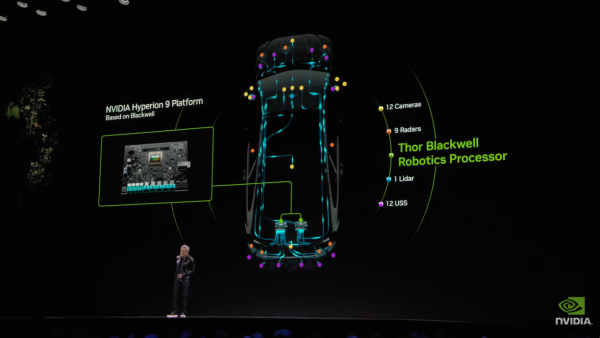
针关于此,英伟达此次发布了新一代车载处理器Thor。

这款芯片的处理才气是上一代Orin的20倍。在安全方面,DRIVE OS赢得了ASIL-D认证,这是汽车功能安全的最高方法,这背后凝合了约15000个工程年的勤苦,使CUDA发展成为一个功能完备、安全可靠的自动驾驶计较平台。
重点七:“通用机器东说念主的ChatGPT时刻降临”,是以英伟达用ISAAC Groot重新界说机器东说念主开发。

谈到机器东说念主变革,黄仁勋说了一句金句:“通用机器东说念主的ChatGPT时刻降临”,并指出了三种最有出路的机器东说念主类型,这三种机器东说念主的私有之处在于,它们不需要特殊的环境校正,不错平直在咱们现存的寰宇中使用:
1、通用型AI或AI代理:因为它们是信息职责者,独一能适合咱们现存的办公环境和电脑系统,就不错职责。
2、自动驾驶汽车:因为东说念主类如故花了一百多年建设说念路和城市,这些基础设施如故完备。
3、东说念主形机器东说念主:不错平直适合为东说念主类盘算的统共环境和器具。
黄仁勋认为,淌若这三种机器东说念主技巧赢得突破,将创造东说念主类历史上最大的科技产业。

但他也指出了刻底下临的关键挑战,止境是在东说念主形机器东说念主的教育方面,与自动驾驶汽车不同(咱们每天皆在产生多数的驾驶数据),集会东说念主类动作示范数据短长常耗时勤劳的。
为了措置这个问题,英伟达冷落了一个创新决策——ISAAC Groot平台,这是一个面向东说念主形机器东说念主开发的完整措置决策。
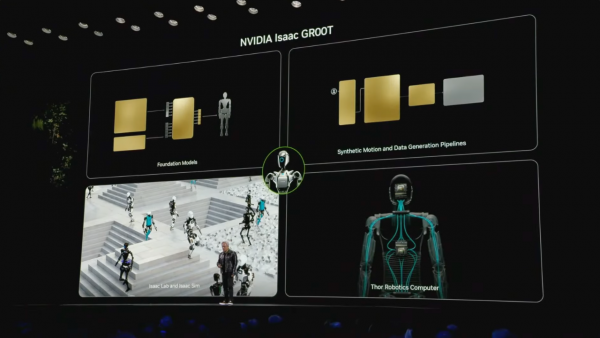
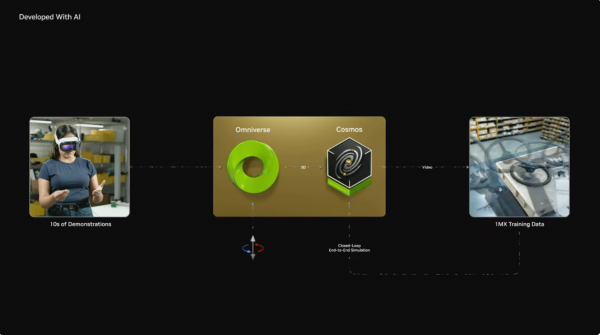
该平台的创新之处在于其私有的数据获取和教育方法:开发者不错使用Apple Vision Pro进行良友操作来拿获数据,通过小数东说念主类示范就能生成大鸿沟教育数据,并欺诈Omniverse+Cosmos进行领域就地化和3D确切感放大,这是一种AI教育方法的创新。
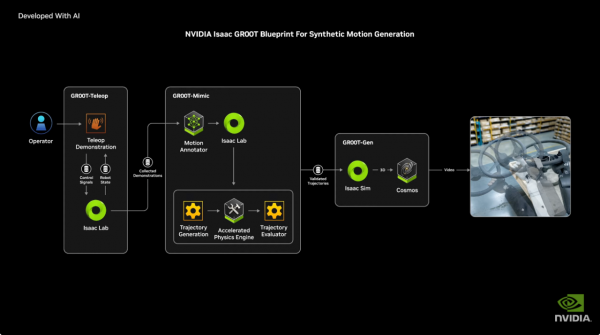
这个方法其实也揭示了机器东说念主领域的紧要变革:咱们正在从专用机器东说念主向通用机器东说念主过渡,而这个治疗的关键在于如何高效地教育这些机器东说念主,通过AI和捏造仿真技巧的连络,咱们不错大大加快这个经过。

重点八:“每个用计较机的东说念主,皆需要AI超等计较机”,是以英伟达用“DIGITS”开启个东说念主AI超算的新纪元。
算作压轴的重磅家具,黄仁勋先容了公司里面的一个样式“Project DIGITS”,展现了将企业级AI计较才气带入个东说念主桌面的洪志。
来源,黄仁勋解释了样式名字的由来。率先样式叫“DIGITS”(Deep Learning GPU Intelligence Training System,深度学习GPU智能教育系统),自后为了与公司其他家具线(如RTX、AGX等)保持一致,简化为DGX。
DGX-1的推出是一个立异性的转换点。在此之前,淌若想要使用超等计较机,你需要建设挑升的设施和基础设施,这对大多数机构来说皆是难以杀青的。而DGX-1改变了这一切,它是一台“开箱即用”的AI超等计较机。黄仁勋还止境提到,2016年他们将第一台DGX-1委用给了OpenAI,其时包括马斯克、Ilya Sutskever在内的团队皆在场。

但当今情况不一样了,AI的应用如故不再局限于磋议机构或创业公司。正如黄仁勋在演讲开动时提到的,AI计较正成为新的计较姿首、新的软件开发姿首,每个软件工程师、工程师、创意艺术家,实践上是每个用计较机的东说念主,皆需要AI超等计较机。
因此,英伟达但愿能作念出比DGX-1更小的设备,于是厚爱发布“Project DIGITS”:一个袖珍化的AI超等计较机。

图:英伟达“Project DIGITS”
该家具基于英伟达的GB110芯片(最小的Grace Blackwell芯片),通过与MediaTek配合开发CPU,并领受NVLink链接到Blackwell GPU,杀青了前所未有的性能突破。

它的盘算理念,是成为一个放在桌面上的云计较平台,非论你的PC是什么系统皆能链接使用,也不错算作Linux职责站使用,复古ConnectX和GPU Direct等技巧,是一台袖珍版的超等计较机。瞻望将在2025年5月上市。

换句话说,英伟达正在将高性能计较从专科数据中心哥哥干,带入闲居用户的办公桌面,这种袖珍化、便携化的AI超等计较机,可能会像个东说念主电脑立异一样,让更多东说念主使用AI技巧进行创新和开发。